
Python 全方面基础知识总结
 技术百科
技术百科  admin
admin  发布时间:2024-03-22
发布时间:2024-03-22  浏览:51 次
浏览:51 次
1、Python 简介
Python 是一门简单易学的,面向对象的,解释型的脚本语言,也是一种开源的、可移植性强的、可扩展性强的高级编程语言,常用于科学计算与人工智能、WEB 开发、金融、云计算等领域。
最近几年来,随着大数据和人工智能的流行,因简单易学、面向对象、以及有丰富的第三方库支持,Python 作为一门解释型的语言也流行了起来,甚至一度呈现出碾压 Java 老大哥的趋势。当然,多掌握点技术对自己来说并不算什么坏事,因此我也开始步入了 Python 的世界,希望在以后能更加深入的开阔自己的眼界,毕竟人生苦短,多用多学 Python。
Python 目前有两个主流的版本方向,Python2.x和Python3.x,鉴于官网2020年对 Python2.x 停止了更新,Python2.7 也正式成为了最后一个Python2.x的版本。对于学习和使用者来说,Python3.x 才是更合理的选择,去官网看看,可下载自己需要的版本,官网链接:https://www.python.org/。
2、Python 下载、安装与使用
我选择的是3.8.5版本,选择 windows,x86-64是64位的下载,下载时注意以下文件的区别:
web-based installer:需要通过联网完成安装;executable installer:通过可执行文件(*.exe)方式安装( 推荐此种类型 );embeddable zip file:嵌入式版本,可以集成到其它应用中。安装的话,基本是傻瓜式的。如果之前安装过Python其他版本,在系统属性-环境变量中,去掉之前版本的相关环境变量配置;安装过程中,选择自定义安装,最好指定目录安装,勾选安装选项中的“添加环境变量”,“预编译标准库”等选项;
安装成功后,验证方式有:
打开 CMD,输入python -V 或 python --version,输出版本信息正常即可;打开系统属性-环境变量,查看用户变量的 path 是否存在安装目录和scripts目录。Python 是一门动态解释型的执行语言,无需编译,定义了后缀为.py的文件,在安装了 Python 环境的机器上去执行,使用 python xx.py 命令即可。
常用的编辑器,推荐一下:
CMD:
自带IDLE:
其他编辑器
基础的编辑器可以用:notepad++,当然,还可以使用:
Eclipse + PyDev (插件:https://www.pydev.org/)Sublime Text ( http://www.sublimetext.com)Atom (https://atom.io/)Visual Studio Code (https://code.visualstudio.com/)PyCharm (https://www.jetbrains.com/pycharm/)3、Python 的数据结构
Python有六种标准数据类型:数字number、字符串str、元组tuple、列表list、集合set、字典dict,而从数据的可变性角度来看,又可分为:不可变的数据类型(数字、字符串、元组) 和 可变的数据类型(列表、集合、字典)。
<1>、数字类型(Number)
Python 不像 Java 或 C 语言那样会有整型(有的还分为长整型、短整型等)、浮点型、布尔类型等之分。在 Python 的世界里,整型(int)、浮点型(float)、布尔(bool)、复数(complex)都统称为数字类型, 在定义变量时,会根据赋值自行推断类型,不需要指定数据类型 。
举例说明:
当然,也可以通过 Python 内置函数 type() 或 isinstance 来获取或判断变量的类型:
<2>、字符串类型(String)
用过 Python2.x 版本写脚本的都知道,字符串是一个很头疼的东西,需要考虑编码,而且使用 print 打印的字符串经常需要转成 unicode才可以输出,这一切在 Python3 做出了重大的改变,因为 Python3 的源码文件默认以 UTF-8 编码,所有字符串默认都是 unicode 字符串。
字符串需要用单引号或双引号表示,支持转义字符,支持对字符串的一系列基本操作 :(比如,字符串截取,重复,连接,格式化,逆序,其他操作符等)
Python3.6 以上版本增强了字符串的格式化操作,使用f-string完全可以替代用%进行格式化,此外Python3.8+ 还支持表达式的输出,如下:
Python 内置模块也提供了许多操作字符串的 API,常见的 API 有:
str(xx):xx转成字符串类型;len(str):计算字符串长度;count(str,start, end):返回指定范围内str在字符串string出现的次数;startswith(str,start, end):在指定范围字符串string内是否存在str开头,存在返回True,否则返回False。endswith(str,start, end)类似。upper():字母转大写,lower():字母转小写。isdigit():字符串是否全部为数字;islower():字符串是否全部小写;spilt():分割字符串;replace(old, new):替换字符串;<3>、元组类型(Tuple)
用(value1,value2,...valueN)形式定义元组,元素可以是任意类型,若一旦被创建将,不能被修改。元组的基本操作也很简单,有切片取值、遍历、删除等。
上面的三种类型都有一个共同点,即元素被创建后具有不变性,特别注意元素不能被修改。比如,上面的字符串使用 str[0]=k 赋值修改元素是不合法的;上面的 tup2[0]=2022 赋值修改元素也是不合法的。
<4>、列表类型(List)
列表类型使用[value1,value2,...valueN]形式定义,列表元素存储是有序的且可重复的。与元组定义一样,列表元素可以是任意类型,不同的是,列表元素是可以被修改的,基本操作如下:
<5>、集合类型(Set)
使用set()函数 或 {value1,value2,...valueN}形式定义集合,集合元素存储是无序的但不能重复。基本操作如下:
<6>、字典类型(dict)
使用{key1:value1, key2:value2,...keyN:valueN}形式定义字典,类似于Java的Map,字典元素存储是键值对。基本操作如下:
4、Python 流程控制语句
Python 流程控制语句也很简单,但与 Java 的流程控制语句相比会有许多不同之处,这里流程控制语句主要有条件语句、循环语句等。条件语句指的是if条件语句,Python 是没有swith-case语句的;循环语句的话,指的是for循环和while循环,Python 是没有do-while循环的,不过for循环和while循环都是可以带有else语句的,表示循环条件不满足时执行else语句。
<1>、条件语句
<2>、循环语句
while 循环,举例:
for循环,举例 9*9乘法表:
Python 似乎精简了流程控制语句中的许多东西,使用起来更加的简便,而实际上,for 循环经常还会和迭代器、生成器一起使用,这里不再说明,在 Python 进阶知识总结再进行梳理。
5、Python 函数的概念
Python 也是一门支持函数式编程的语言,而函数式编程的特点为:支持非纯函数式编程、支持闭包、支持高阶函数、及有限度的支持匿名函数。作为入门的知识点,先梳理下 Python 函数的基本概念。
Python中的函数定义也很简单,如图所示:
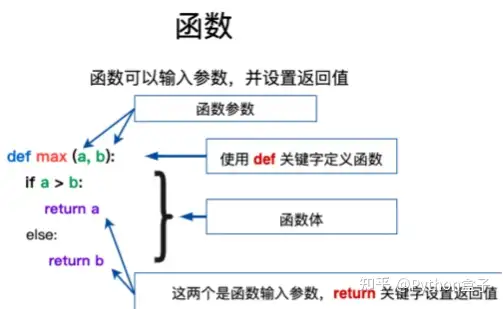
函数定义:
通过def关键字标识,入参可以无参也可以有参,函数体内可以有返回值也可以没有返回值;入参的话,写在()内,注意一些特殊传参,比如*args,**kwargs等可变长参数,它们的区别在于:*args传入元组类型,可有多个,**kwargs传入字典类型,也可有多个;书写函数需要注意行的缩进,注意英文冒号:不要遗漏等;参数传递:
不可变类型参数传递 (如数字、字符串、元组等类型),本质是按值传递。
可变类型参数传递 (如列表、集合、字典等类型),本质是引用传递。
注意:函数也能作为参数进行传递的,这就是高阶函数的特征,后面进阶总结时再详细说明。
变量作用域:
模块内存在两种类型的变量,即局部变量和全局变量,通常以变量是否声明在函数体内来区分 局部变量 和 全局变量 。如果需要在函数体内定义全局变量,需要加上global关键字声明。
6、Python 异常处理
Python 作为一门高级语言,也有着自己的一套异常处理机制。如果代码里没有任何捕获异常处理,Python 会调用默认的异常处理器处理。程序运行前,不管你是否是类型错误(TypeError),还是名称未定义(NameError),还是数组越界(IndexEoor)等其他异常,首先都会进行语法错误(SyntaxError)检查,例如:
常见的 SyntaxError 有:
因此,平时需要多注意规范书写,避免低级的语法错误。在 Python 的世界里,运行期间检查到的错误称为异常,大多数的异常都不会被程序去处理,而是以错误的形式展示出来,大多数的异常的名字都以"Error"结尾,和标准的异常命名一样。
Python 有三种异常处理结构:即 try...except...finally语句块、assert 断言和 with 语句。
<1>、异常代码块
Python 也可以主动捕获异常,捕获异常的代码块完整结构及相关用法,如下所示:
<2>、assert断言
断言,是一种判断表达式,当表达式结果为False时会触发异常,完整的断言语法为:
举例说明:
<3>、with语句块
像 Java 语言异常处理时,使用异常语句块书写的代码显得特别的臃肿,然而 Python 异常处理的话,除了可以使用try...except...finally语句块外,还可以使用with语法,如果对比二者的代码量,一定会为 Python 代码的短小而精简震撼,以使用游标查询数据来举例说明:
try...except...finally:
with...as语句:
with 语句强大之处在于,不用我们再去手动捕获异常,不用再去一个个close资源连接,将这一系列的工作都交给了 Python 内部去处理。with 语句在操作文件读写,操作数据库等方面很实用,推荐使用。
7、Python 文件读写操作
os 模块是 Python 的内置模块,它提供了很多的 API 方法用来操作目录和文件,我们可以在 Python 安装目录找到 doc,里面可以找到 os 模块的文档说明,os 模块的主要用途如下:
要进行文件读写操作的话,使用open()函数;要操作文件属性及路径的话,使用os.path模块;要读取命令行中文件的话,使用fileinput模块;要操作临时目录或文件的话,使用tempfile模块;更高级的目录或文件操作,使用shutil模块。这里,重点说明下文件的读写操作。在计算机的世界里,文件后缀的格式多不胜数,我们只需要知道常见的文件格式就行,比如:.txt、.log、.json、.csv、.xls/.xlsx、.doc/.docx、.ppt、.xml、.yml等。
< 1 > 、文件读写API
读写文件的方法为open(),通常有两种写法:
模式 mode 参数有:

文件读取操作有关的方法有:
f.read():读取文件内容;f.readline(size):读取一行,size表示读取该行多少个字符;f.readlines():读取文件所有的行,以列表的形式返回;f.tell():返回文件当前的位置;f.seek(offset[, whence]):移动文件读取指针到指定位置,offset:开始的偏移量,whence:0 从文件开头开始算起,1 从当前位置开始算起,2 从文件末尾算起;f.close():关闭文件,释放资源。文件写入操作有关的方法有:
f.write(str):将字符串写入文件,返回的是写入的字符长度;f.writelines(sequence):向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符;f.flush():刷新文件内部缓冲,直接把内部缓冲区数据立刻写入文件, 而不是被动等待输出缓冲区写入。普通的 open() 操作,无论读写,在最后都要使用 close() 方法手动关闭连接,这一点不要忽略了。而如果使用的是 with open() 语法形式,则不需要手动去关闭,举例说明:
执行结果:

< 2>、读写.txt/.log文件
使用上面的有关的API即可实现,比较简单。
< 3>、读写.json文件
第一步:导入json模块;第二步:借助该模块dump()实现写入文件功能, load()实现读取文件功能;更多API可以参考:https://docs.python.org/zh-cn/3/library/json.html 。举例说明:
执行结果:

< 4>、读写csv文件/excel文件
csv文件已在上面的演示中用过了,不再举例。excel文件与csv文件看上去很相似,但依赖的模块和操作却不一样,excel文件的后缀是.xls 或 .xlsx,有许多模块支持 excel 的读写操作,比如:
openpyxl :A Python library to read/write Excel 2010 xlsx/xlsm files;xlrd + xlwt + xlutils :三个模块搭配使用,对excel读写和复制等操作。这里,使用 openpyxl 模块,使用pip命令下载:
举例说明:
执行结果:

日志:

需要注意,读写excel时,单元格的坐标位置起始值是(1,1),load_workbook用于写excel、Workbook用于读取excel。更多API参考:https://openpyxl.readthedocs.io/en/stable/index.html#。
<5>、读写Word文件
Word 文件的后缀有.doc 和 .docx 格式,以下模块支持 word 文档的读写:
python-docx :只支持.docx 格式,但可以将 .doc 转成 .docx 格式,从而间接支持 .doc 格式;(API参考:https://python-docx.readthedocs.io/en/latest/index.html)win32com :调用系统的word功能,可以同时支持.doc 和 .docx 格式。这里,使用 wun32com模块,使用pip命令下载:
我们能如此方便的调用 Word,得益于其底层的 COM(组件对象模型)可以被任意语言调用,操作 word 时需要知道以下对象:
Application :表示Word应用。包含了菜单栏、工具栏、命令以及所有文档等;Documents :表示文档,可有多个。有打开Open()、创建Add()等API;Selection :表示当前窗口的光标焦点或选择范围。有输入TypeText()、复制Copy()、粘贴Paste()、删除Delete()、全选WholeStory() 、左移MoveLeft()、右移MoveRight(start, end)等API;Range :表示连续区域,用于区分文档不同位置,Range(0, 0)表示开始位置,Range()表示文末位置。对 Selection 和 Range 也可以设置字体 Font、设置段落 ParagraphFormat 、设置 PageSetup、设置样式 Styles等。举例1 : 创建Word文档,并转储到txt文件中
转储txt内容:

举例2 : 读取Word文档,并转储到txt文件中
<6>、读写其他文件
文件类型那么多,不可能面面俱到的去演示读写操作的,从上面的Demo可以看到通用的思路如下:
要先明确是否需要导入模块,可以自行百度或去pip官网进行依赖查询;尽量找到详细可参考的文档读写操作API,并亲测该方法的功能后再使用;8、Python 模块
Python 流行而强大之处在于支持丰富的第三方库,这为实现很多的拓展功能提供的可能。通常使用 pip 命令安装需要的第三方模块,但使用 pip 命令之前,请确保机器上安装了 Python 环境,并在环境变量中配置了 Scripts 目录。
pip 支持的第三方模块,可以去官网查询相关依赖:https://pypi.org/ 。当然,有必要了解下 pip 的相关命令:
pip list:查看已安装的第三方模块pip install模块名:安装第三方模块pip show --files 模块名:查看是否已安装的模块信息pip list --outdated:检查哪些模块名需要更新升级pip install --upgrade 模块名:更新升级第三方模块pip uninstall 模块名:卸载第三方模块pip --help:帮助命令以图像处理模块(Pillow)为例,演示:
第一步,先下载该模块:
第二步,查看该模块的详细信息:
之后便可以愉快的使用 Pillow 模块提供的API了~~
这里需要注意区分:Python 自带模块与第三方模块?
Python自身带有内置的模块供开发者使用,在安装的时候勾选了文档的话,可以通过提供的文档查看有哪些内置模块:http://localhost:57952/ 。第三方模块的话,需要额外去下载才能被使用,可以先查询是否存在再下载或者升级。不论是自带模块,还是第三方提供的模块,导入的方式有下面几种 :
值得注意的是用法4,可以使用但不推荐。使用*导入模块中所有的内容,这里会把私有变量和私有函数除外的所有变量/函数/类等导入,容易造成混乱,也可能会覆盖当前模块的同名变量或同名函数,所以要注意这类规范。
Python 模块很简单,深入起来也有点东西,下面是我学习过程中遇到的问题及思考过程,也顺便记录下。
思考一个问题,在一个模块中,我们使用了其他很多的模块也存在的变量或函数,为什么在这个模块中能正常使用而不发生冲突呢?
这是因为 Python 中的每个模块都拥有各自独立的符号表,每个模块中的所有函数都会在符号表中被当做全局符号使用,每个模块间的全局变量相互是隔离的,因此能正常使用。

再思考一个问题,比如当前模块A要引入模块B或模块B中指定的变量或函数,在第一次运行程序时,模块B中的变量或函数会放到模块A中的符号表中,那我怎么保证模块B的某段代码块不会再模块A中被执行呢?
这个问题的答案发现是我之前疑惑已久的问题,那就是为什么类的模块里经常要写以下代码呢:
其实,__name__属性是模块的私有属性,通过 __name__==__main__: 能控制某些代码块只在本模块内会被使用,不会在引入该模块的模块里使用!
接着,思考更复杂的一些问题。假设存在以下目录结构:(src下有两个模块mod1.py和mod2.py、两个包p1和p2,而p1包和p2包又存在各自的模块,p1包下为mod.py和mod1.py,p2包下为mod.py和mod2.py)

<1>、导入平级目录的模块
在src目录下的mod1.py中导入src下的mod2.py( 同级目录的模块引入 ),直接按模块名称导入即可。 如果当前模块mod1存在与模块mod2的同名变量或同名函数时,使用导入模块名.变量 或 导入模块名.函数区分 。
mod2.py :
mod1.py :(测试)
结果:

<2>、导入下级子目录模块
在src目录下的mod1.py中导入p1包下的mod.py( 父包引入子包 ),这里使用包名.模块名导入即可, 包可以理解为Python管理模块命名空间的方式,最好在该包下加入__init__.py模块标识 。 如果当前模块mod1存在与模块mod的同名变量或同名函数时,使用导入包名.模块名.变量 或 导入包名.模块名.函数区分。
p1包下的mod.py
mod1.py :(测试)
结果:

<3>、导入上级父目录模块
在p2包下的mod2.py中导入src目录下的mod2.py( 子包引入父包 ),使用 import src.mod2 as smod2 方式会报错:ModuleNotFoundError: No module named src 。
p2包下的mod2.py:(测试,报错!!!)
这里,我接着测试了p2包的mod2模块导入p1包的mod模块( 兄弟包模块引入 ),报错: ModuleNotFoundError: No module named p1 。
额,这结果太让人疑惑了,我在想上面这两报错种情况的出现, 应该是与Python搜索模块的机制有关系的,那有必要搞清楚Python搜索模块的顺序 :
优先搜索内置模块(上面的自定义模块不属于内置模块)接着搜索sys.path(打印出来sys.path都有哪些东西?)可以看到,列表返回的搜索顺序为:
自定义模块所在的根目录,这里是p2包;标准库的目录;最后是site-packages,即第三方扩展模块的目录;由此可以清晰的看到, 对于自定义模块所在的包会成为根目录,而根目录是没有父目录或者兄弟目录的,这就解释了为什么子包引入父包、兄弟包之间引用会报错找不到父包找不到兄弟包 。因此,平时引用自定义模块时应当避免这些情况的发生,做到规范引入模块!!!
最后呢,值得关注下__init__.py模块的作用,前面提及到该模块是为了标识当前目录是一个包,能够避免影响到搜索路径中的有效模块,这也是一种约定俗成的规范吧。有时候该模块可能会定义一个__all__的私有变量,那么它是干嘛用的呢?
比如有一个场景:使用from p2.mod import * ,预期的结果是将自定义p2包下mod.py模块的所有的非私有变量/函数全部引入到了当前模块里,假如内置模块或标准库也存在p2包及包下的mod.py模块,那么进行搜索路径模块时可能就无法区分是否来自于自定义模块了。
此时,通过自定义包p1下的__init__.py模块维护一个__all__变量,里面存放着该包下的所有模块列表,当搜索路径模块时根据它就能唯一确定模块的位置了。__all__变量定义如下:
当该包发生更新时(如修改模块名称,或新增模块名),记得维护下这个变量的列表内容!!!
模块很简单,深入起来也有点东西,通过深入了解后,总结一下几个值得注意的规范:
慎用 import module from * 方式导入;引入包的模块时,避免引入它的父包和兄弟包下的模块;自定义包下最好定义一个__init__.py模块,该模块里最好定义一个__all__变量,当该包更新时及时维护__all__变量;Python搜索路径模块的大致顺序为:内置模块 > 自定义模块 >环境变量目录下的模块 > 标准库目录下的模块 > 第三方扩展目录下的模块等,尽量不要在除了自定义模块目录外的其他目录下定义包或模块。Python 基础知识的总结,就到这~
 售前咨询专员
售前咨询专员